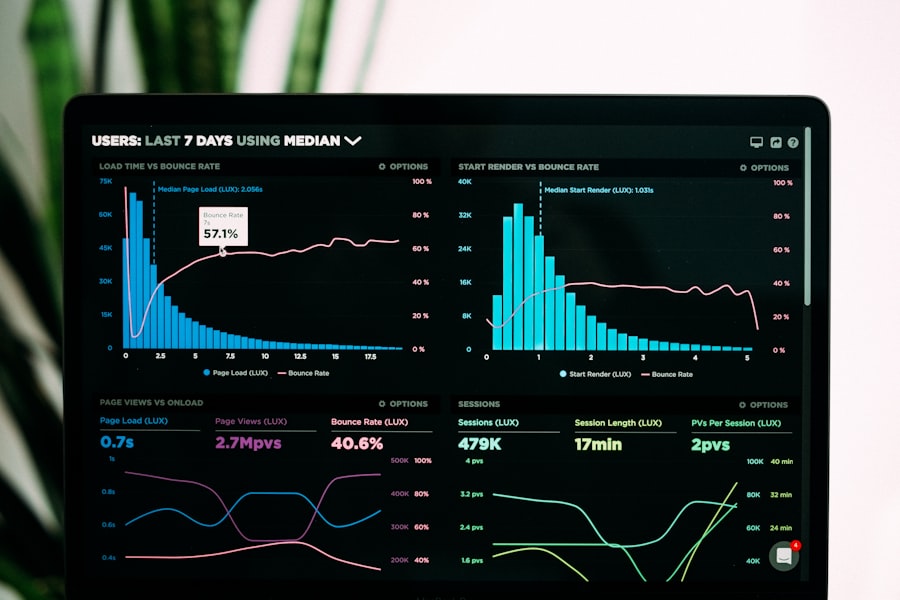
The difference is not reporting.
It’s implementation quality.
A surprising number of cost assessments end with a 40-page spreadsheet and no engineering follow-through. The gap isn’t visibility — it’s turning spend signals into safe infrastructure changes.
Optimization that survives engineering scrutiny.
We don’t generate findings the team will reject because they “feel risky.” Every recommendation comes with the technical reasoning, the rollback path, and the exact Terraform diff. The team reads our report and ships it — they don’t have to re-justify it internally.
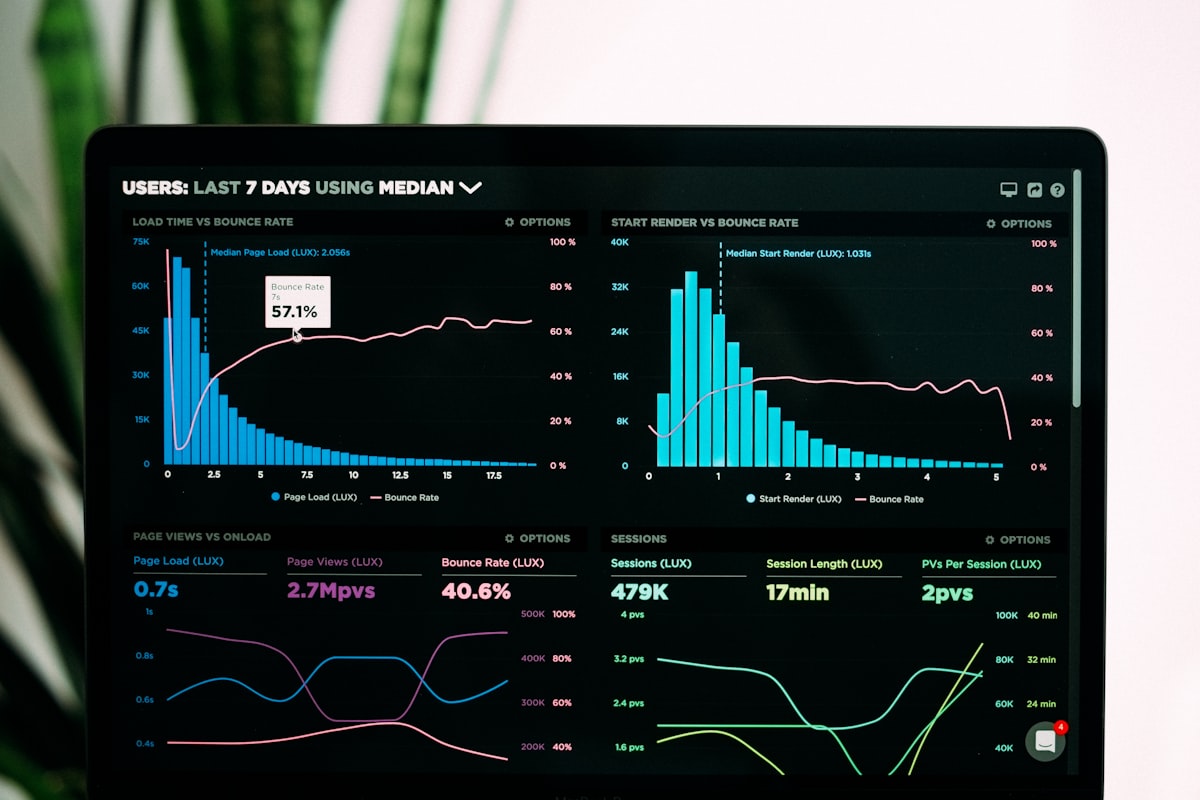
Engineers, not accountants
Every audit is led by a senior AWS architect who’s actually shipped multi-account production environments. We understand why a workload runs the way it does before we recommend changing it.
Actionable remediation steps
Each finding ships with the affected resources (EC2 instance IDs, EBS volumes), step-by-step instructions, CLI commands, and Terraform module changes. Your team executes — they don’t research.
20–40% hard savings
We target high-impact architectural optimizations that tools miss. Median client across our last 22 audits saw a 35% monthly spend reduction within 60 days — without any production performance impact.